
簡可信離線批量OCR識別
v2.1.0.0 綠色版- 軟件大小:134 MB
- 軟件語言:簡體中文
- 更新時間:2022-11-28
- 軟件類型:國產(chǎn)軟件 / 文字處理
- 運行環(huán)境:WinXP, Win7, Win8, Win10, WinAll
- 軟件授權(quán):免費軟件
- 官方主頁:http://www.gaya-soft.cn/
- 軟件等級 :
- 介紹說明
- 下載地址
- 精品推薦
- 相關(guān)軟件
- 網(wǎng)友評論
簡可信圖片批量OCR識別軟件提供簡單的文字識別功能,打開圖像到軟件就可以立即點擊識別功能讀取圖像上的文字,從而將其輸出為PDF或者是TXT格式,方便用戶復(fù)制文本內(nèi)容使用,您可以將多張圖像添加到軟件轉(zhuǎn)換為PDF文檔,將拍攝的文檔照片,截圖的內(nèi)容添加到軟件就可以選擇識別導(dǎo)出為雙層的PDF文件,以后就可以通過PDF格式查看圖像內(nèi)容了,內(nèi)置專業(yè)的ocr模板識別工具,可以快速識別各種證件關(guān)鍵信息,可以識別發(fā)票掃描、高拍儀關(guān)鍵信息,也可以在軟件編輯新的識別模板,方便識別指定的內(nèi)容。
軟件功能
1、可以同時對大量PDF文檔,圖片文件進行OCR識別。
2、將您的圖片文檔,PDF文件轉(zhuǎn)換為可編輯的文本,可以批量輸出雙層PDF,文本文件等。
3、軟件使用Tesseract5 API, 速度快,質(zhì)量高,支持多線程處理。
4、本系統(tǒng)可以實現(xiàn)內(nèi)網(wǎng)環(huán)境下本地化部署,不需要把文件上傳到互聯(lián)網(wǎng),可以保障文件安全,不會導(dǎo)致泄密。
5、軟件完全免費,沒有任何時間和功能限制。
軟件特色
1、簡可信圖片批量OCR識別軟件可以幫助用戶輕松識別文本內(nèi)容
2、如果你的圖像上有文本內(nèi)容就可以選擇識別
3、可以將各種紙質(zhì)的文件拍照,隨后導(dǎo)入圖像到軟件識別
4、各種營業(yè)執(zhí)照、證件信息、書本信息都可以通過拍照的方式添加到軟件識別
5、可以批量加載圖像到軟件識別,可以輕松查看識別的文字
6、可以在軟件預(yù)覽圖像,可以調(diào)整適合當(dāng)前頁面的寬度和高度,方便預(yù)覽圖像中的文字
7、支持中文、英文識別,可以手動配置百度API識別文字
使用方法
1、將軟件安裝到電腦,地址是C:UsersadminAppDataLocalgayaOcr
2、添加需要識別的內(nèi)容,可以將圖像添加到軟件
3、在頂部可以調(diào)整圖像到適合的頁面寬度以及頁面高度,也可以自由縮放圖像
4、點擊識別全部并導(dǎo)出功能,彈出保存選項界面,可以選擇保存為PDF,可以選擇導(dǎo)出ocr識別文本
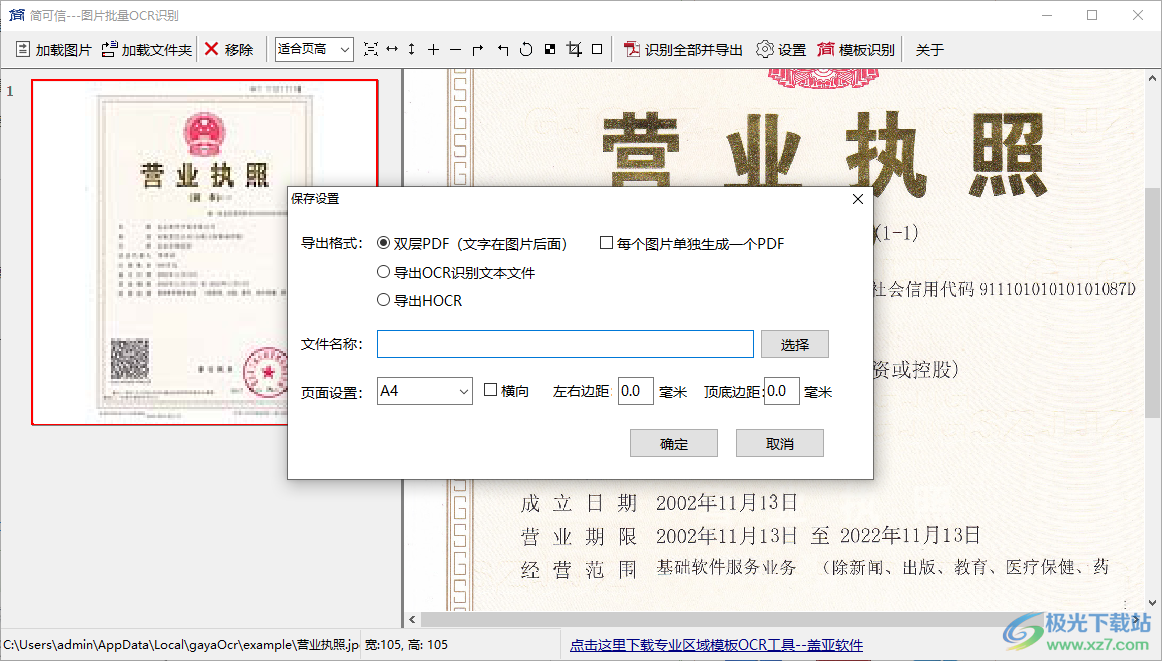
5、如果需要保存為TXT就選擇導(dǎo)出ocr識別文本,也可以選擇將圖片單獨生成PDF
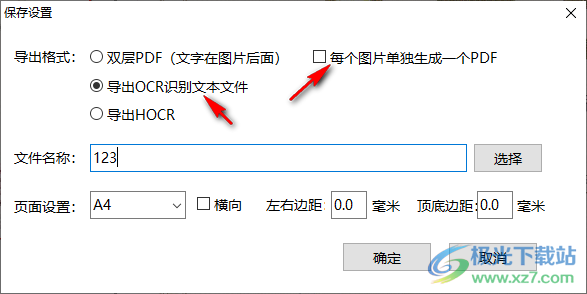
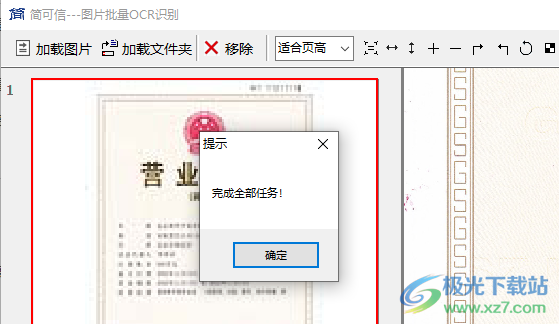
6、識別全部任務(wù)完畢,可以進入軟件安裝地址找到輸出的文本
7、在C:UsersadminAppDataLocalgayaOcrbin地址下就可以查看到識別完畢的TXT,如果您選擇保存PDF,這里就會顯示PDF文件
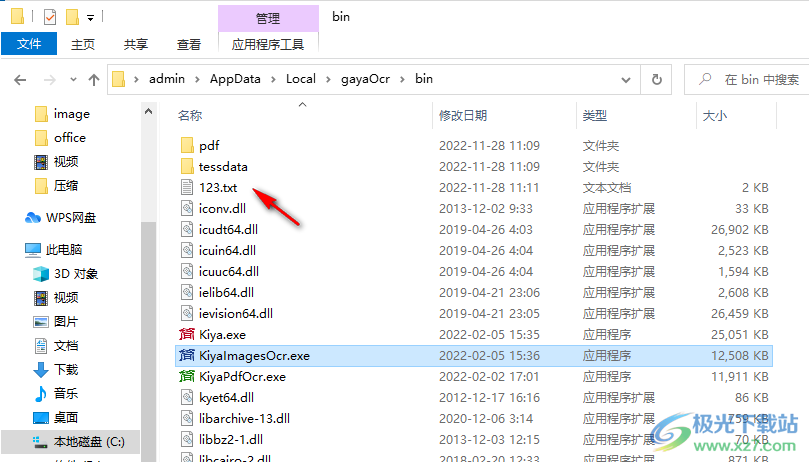
8、識別的效果就是這樣的,無法精準(zhǔn)識別文字內(nèi)容
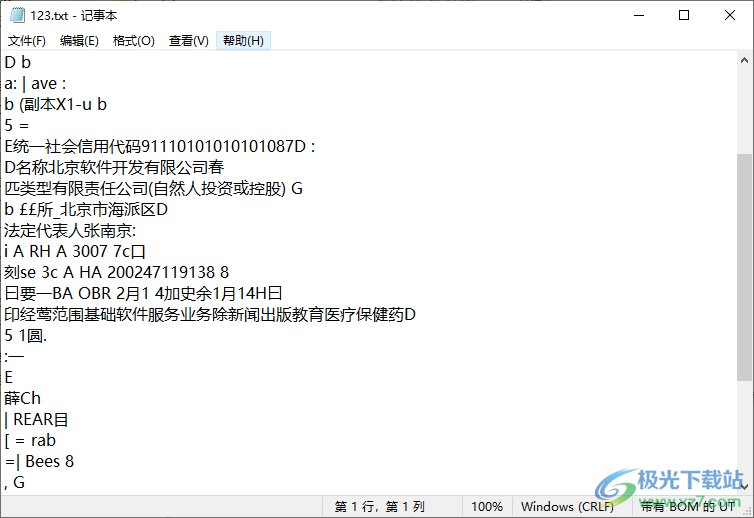
9、如果添加的是英文的內(nèi)容就可以進入設(shè)置界面選擇識別英文,可以設(shè)置識別線程數(shù)
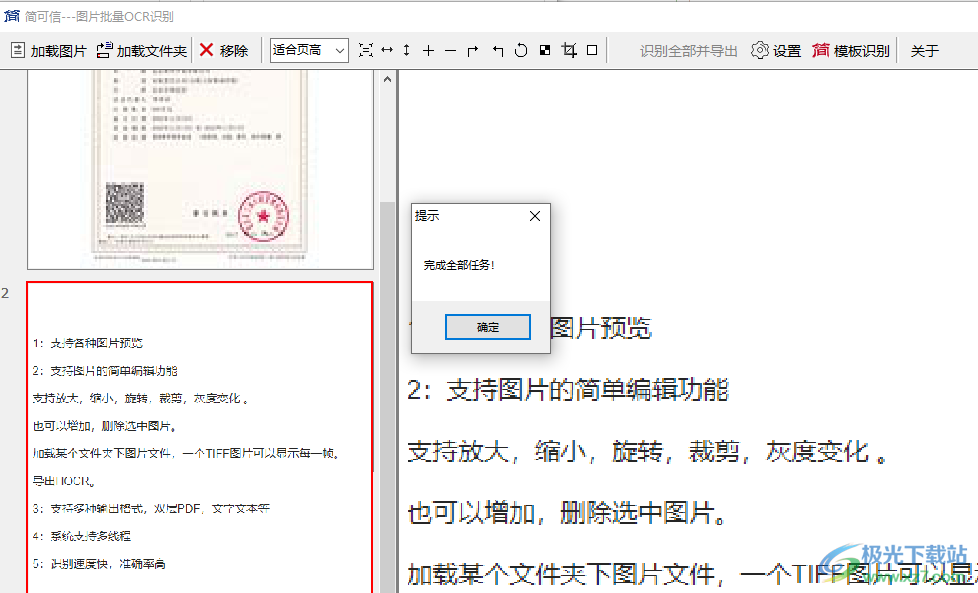
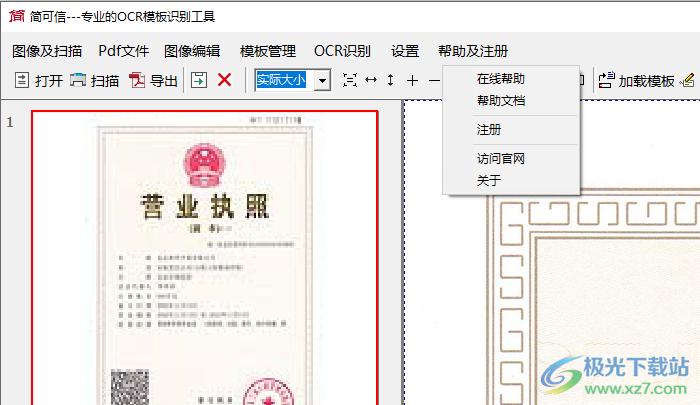
10、可以繼續(xù)加載其他圖像到軟件識別,也可以在右上角啟動“模板識別”功能
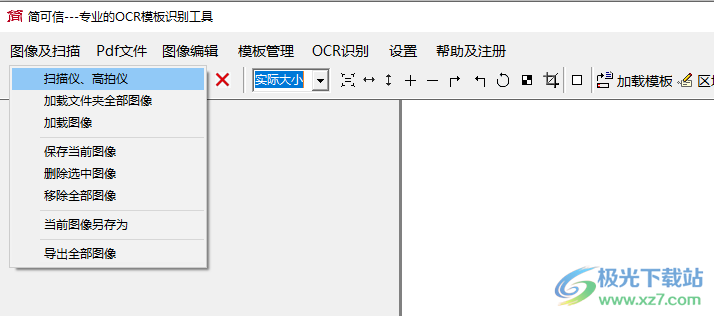
11、進入專業(yè)的ocr模板識別工具界面,支持掃描儀、高拍儀、加載文件夾全部圖像、加載圖像
12、編輯單頁OCR識別模板、增加多頁OCR識別模板、當(dāng)前圖片識別保存為模板、模板管理、打開模板文件夾、上傳下載模板(服務(wù)器)
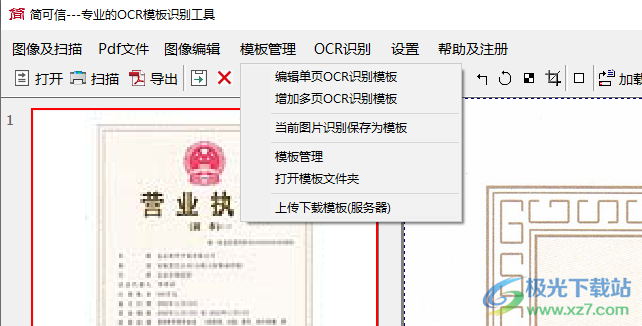
13、加載OCR識別模板、增加一個識別區(qū)域、按模板識別當(dāng)前圖像、按模板識別全部圖像、顯示/隱藏OCR識別結(jié)果
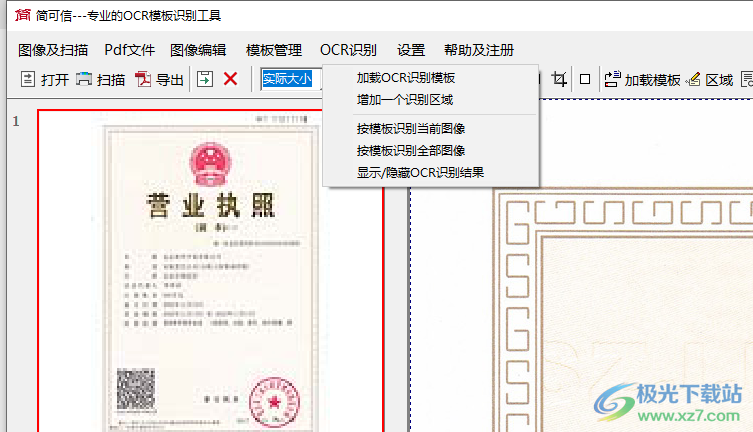
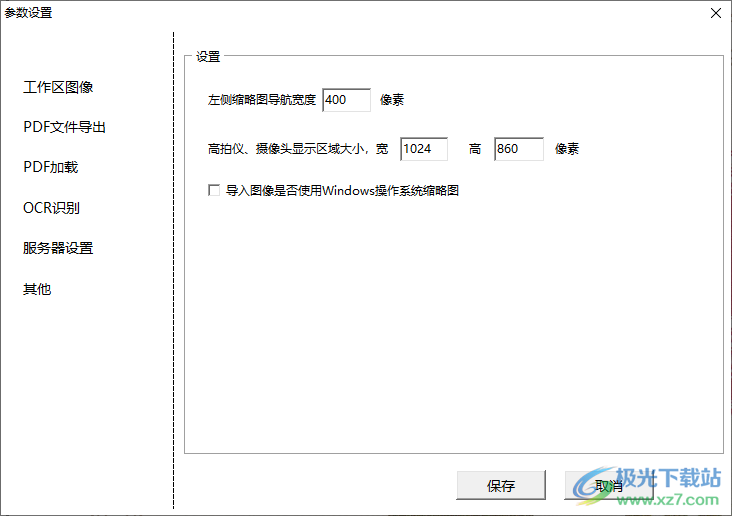
14、設(shè)置界面:左側(cè)縮略圖導(dǎo)航寬度400像素、高拍儀、攝像頭顯示區(qū)域大小,寬1024高860像素、導(dǎo)入圖像是否使用Windows操作系統(tǒng)縮略圖
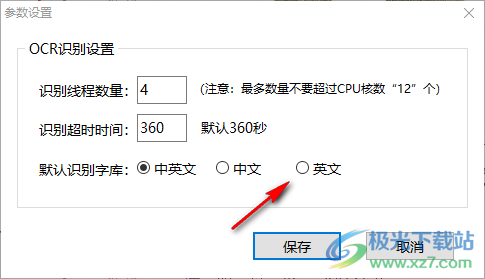
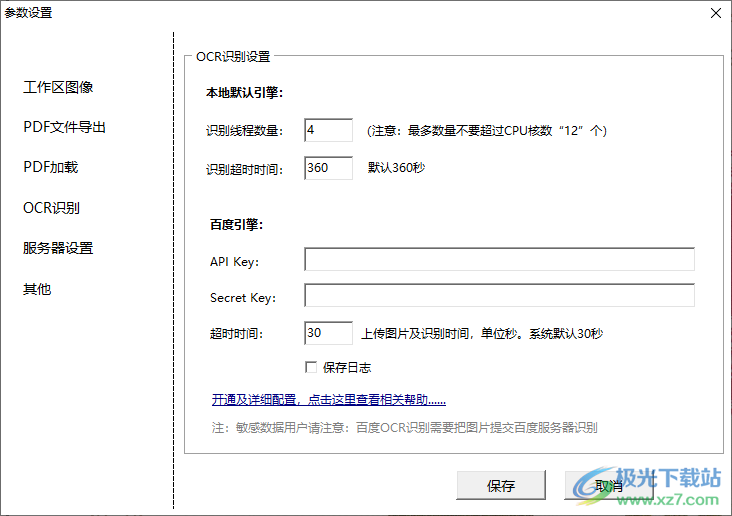
15、OCR識別設(shè)置
本地默認(rèn)引擎:
識別線程數(shù)量:4(注意:最多數(shù)量不要超過CPU核數(shù)“12”個)
識別超時時間:360,默認(rèn)360秒
百度引擎:可以在這里配置API
16、如果需要查看更多的功能可以點擊在線幫助,可以查看幫助文檔,可以進入官方網(wǎng)站
下載地址
- Pc版
簡可信離線批量OCR識別 v2.1.0.0 綠色版
本類排名
本類推薦










裝機必備
換一批























- 聊天
- qq電腦版
- 微信電腦版
- yy語音
- skype
- 視頻
- 騰訊視頻
- 愛奇藝
- 優(yōu)酷視頻
- 芒果tv
- 剪輯
- 愛剪輯
- 剪映
- 會聲會影
- adobe premiere
- 音樂
- qq音樂
- 網(wǎng)易云音樂
- 酷狗音樂
- 酷我音樂
- 瀏覽器
- 360瀏覽器
- 谷歌瀏覽器
- 火狐瀏覽器
- ie瀏覽器
- 辦公
- 釘釘
- 企業(yè)微信
- wps
- office
- 輸入法
- 搜狗輸入法
- qq輸入法
- 五筆輸入法
- 訊飛輸入法
- 壓縮
- 360壓縮
- winrar
- winzip
- 7z解壓軟件
- 翻譯
- 谷歌翻譯
- 百度翻譯
- 金山翻譯
- 英譯漢軟件
- 殺毒
- 360殺毒
- 360安全衛(wèi)士
- 火絨軟件
- 騰訊電腦管家
- p圖
- 美圖秀秀
- photoshop
- 光影魔術(shù)手
- lightroom
- 編程
- python
- c語言軟件
- java開發(fā)工具
- vc6.0
- 網(wǎng)盤
- 百度網(wǎng)盤
- 阿里云盤
- 115網(wǎng)盤
- 天翼云盤
- 下載
- 迅雷
- qq旋風(fēng)
- 電驢
- utorrent
- 證券
- 華泰證券
- 廣發(fā)證券
- 方正證券
- 西南證券
- 郵箱
- qq郵箱
- outlook
- 阿里郵箱
- icloud
- 驅(qū)動
- 驅(qū)動精靈
- 驅(qū)動人生
- 網(wǎng)卡驅(qū)動
- 打印機驅(qū)動


網(wǎng)友評論